


Why Organizations are Modernizing their Applications with Distributed, Multi-Cluster Kubernetes Deployments
An exploration of the substantial advantages and opportunities for evolving from a centralized cluster deployment to a distributed multi-cluster topology
Introduction
According to a survey from the Cloud Native Computing Foundation, more than 92% of respondents worldwide have adopted containers in their production environments, and 83% of those are using Kubernetes to orchestrate those containers.
 Image source: CNCF Survey Report (2020)
Image source: CNCF Survey Report (2020)
As these organizations mature their containerized applications, many are looking to multi-cluster, multi-region, multi-provider deployments.
Why?
A distributed multi-cluster deployment offers numerous, substantial benefits over centralized clusters in terms of availability, resilience, scalability, performance, cost and more. Let’s look at each benefit in turn, and then discuss what organizations need to consider in adopting a distributed, multi-cluster, multi-region topology.
But before we do that, it’s important to frame what we mean by distributed, multi-cluster, multi-region deployments.
Understanding Multi-Cluster Deployments
When looking at containerized Kubernetes environments, it’s important to understand that they vary along several vectors. First and foremost, they may be single or multi-cluster.
While the definition of multi-cluster might be obvious to anyone comfortable with basic arithmetic, there are important nuances. A true multi-cluster deployment does not simply mean having more than one cluster. It means orchestrating and managing those clusters as though they were a single platform. While you certainly could set up and control different clusters using separate control planes and tooling, that would be both inefficient and negate many of the benefits to be had.
That doesn’t mean that clusters need to be the same; far from it. Each cluster is independent, and controls its own provisioning, services, security schema and resources.
 Image source: Gartner Blog
Image source: Gartner Blog
Second, the deployment may be centralized or distributed. It is entirely possible, and often advantageous, to have multiple clusters within a centralized hosting environment, for instance so you can have separate clusters for staging/testing and production (more on this later). Conversely, you can distribute these clusters more broadly across hosting environments (for instance, on-prem and cloud), providers, even geographies. Each offers its own benefits and challenges, so when looking at a distributed environment it’s important to consider how distributed? As we’ll get into, it’s generally true that the more distributed, the better.
Finally, a deployment can be single-region or multi-region. A distributed multi-cluster deployment that’s limited to North America, for instance, will have different considerations than an application workload that needs to address the needs of users in both North America and the European Union. A truly global deployment will have its own set of unique requirements and challenges.
In a very real sense, this creates a progression in Kubernetes containerization that typically mirrors application maturity, from single cluster to centralized multi-cluster to distributed multi-cluster to, ultimately, multi-region edge deployments. And it’s at the edge that the true magic happens for users and organizations, as we’ll see.
Interestingly, there’s an important subtext to understand in the relationship between Kubernetes containerization and workload distribution. Simply put, the lightweight portability of containers makes them ideally suited to distribution, while their abstraction facilitates deployment to non-homogenous federated compute platforms. Moreover, Kubernetes adds the orchestration needed to best coordinate this sort of distributed multi-region, multi-cluster topology.
In other words, organizations that have already adopted Kubernetes are primed to rapidly adopt modern edge deployments for their application workloads. Even those that are still at the single-cluster stage are in position to rapidly leap-frog to the distributed edge. Recent research by SlashData on behalf of the Cloud Native Computing Foundation confirms this correlation between edge, containers, and Kubernetes, noting developers working on edge computing having the highest usage of both containers (76%) and Kubernetes (63%) of surveyed segments.
Centralized Kubernetes Container Deployments
For most organizations, initial Kubernetes adoption starts with centralized clusters. Primarily this is due to simplicity: whether single or multi-cluster, a centralized deployment eliminates the need to deal with the underlying complexities that can be involved in distributed topologies, as covered in our white paper on Solving the Edge Puzzle.
Once they’ve started down this path, it’s also the more familiar approach, allowing them to continue using the same tooling and management strategies they’ve become comfortable with (kubectl, Helm Charts, etc.). This combination of simplicity and familiarity holds true whether the deployment is centralized in a data center, or through a single cloud provider or hyper scaler.
What these organizations need to weigh, however, is what they’re giving up with centralized clusters. Are the benefits of a distributed multi-cluster deployment worth the added complexity? Moreover, what if we can eliminate that complexity? What then?
Building for Edge is a complex and always shifting puzzle to be solved and then managed

The Benefits of Distributed Multi-Cluster Deployment
As noted, application maturity and scale tend to drive distributed multi-cluster adoption. The question is: why? What are the advantages and benefits of a distributed topology over centralized clusters? As importantly, does the breadth of distribution matter? Are organizations that adopt a multi-region, multi-provider approach gaining advantage over those that don’t? Let’s dive in.
Every year there are reports of wide swaths of the internet ‘going dark’ and taking down well-known brands and applications. Invariably, those issues are traced back to problems within a particular provider network. Distributed multi-cluster deployments help mitigate those risks.
Availability and Resiliency
By mirroring workloads across clusters, you increase availability and resiliency through elimination of single points of failure. At its most basic level, this means using one cluster as a backup or failover should another cluster fail. As you increase cluster distribution outside of a single data center/cloud instance to stretch across clouds and providers, you further minimize risk – from failure of single endpoints within a provider network, or even failure of an entire provider network – by ensuring your application can fail over to other endpoints or providers.
Vendor Lock-in
Avoiding reliance on a single vendor is an operational mantra for many organizations, making the ability to distribute workloads not only across locations, but across providers a key advantage. This multi-vendor approach improves pricing flexibility, as well as ensuring better continuity and quality of service. Similarly, this can help mitigate data lock-in, whereby it can become prohibitively expensive to migrate data off a provider’s network.
In fact, a distributed multi-cluster, multi-vendor approach even helps mitigate managed Kubernetes lock-in, ensuring you are not committed to a particular provider’s version of Kubernetes and any proprietary extensions supported by a specific cloud provider’s managed Kubernetes service.
Performance and Latency
According to a recent survey of IT decision makers by Lumen, 86% of organizations identify application latency as a key differentiator. And the single best way to reduce latency is to reduce geographic distance by physically placing applications closer to the user base.
Distributed multi-cluster Kubernetes facilitates this strategy, allowing organizations to use an edge topology to process data and application interactions closer to the source. This becomes especially important – in fact, arguably a necessity – for applications that have a global user base, where multi-region edge deployments can geographically distribute workloads to best reduce latency while efficiently managing resources (e.g. spinning up/down infrastructure to adapt to “follow the sun” or other regional and ad hoc traffic patterns).
Organizations that elect a centralized approach are, by definition, treating users outside of the primary geography as second-class citizens when it comes to application performance. In fact, this is the primary consideration when organizations choose a particular cloud instance for deployment (e.g. AWS EC2 US-East): where are most of my users based, so those within or close to that region will enjoy a premium experience? The unspoken corollary is that as customers get geographically further from that particular region, application performance, responsiveness, resilience and availability will naturally degrade. In short, this is the default “good enough” cloud deployment for application workloads that cater largely to a home-grown user base. As these applications mature and broaden adoption, this strategy becomes increasingly tenuous, and organizations find themselves compelled to move workloads to the edge.
Scalability
A closely related factor: running multiple distributed clusters also improves an organization’s ability to fine tune and scale workloads as needed, providing greater flexibility than centralized clusters. This scaling is required when an application can no longer handle additional requests effectively, either due to steadily growing volume or episodic spikes.
It’s important to note that scaling can happen horizontally (scaling out), by adding more machines to the pool of resources, or vertically (scaling up), by adding more power in the form of CPU, RAM, storage, etc. to an existing machine. There are advantages to each, and there’s something to be said for combining both approaches.
A distributed multi-cluster topology facilitates this flexibility in scaling. Among other things, when run on different clusters/providers/regions, it becomes significantly easier to identify and understand which particular workloads require scaling (and whether best served by horizontal or vertical scaling), whether that workload scaling is provider- or region-dependent, and ensure adequate resource availability while minimizing load on backend services and databases.
Those familiar with Kubernetes will recognize that one of its strengths is its ability to perform effective autoscaling of resources in response to real time changes in demand. Kubernetes doesn’t support just one autoscaler or autoscaling approach, but three:
- Pod replica count – This involves adding or removing pod replicas in direct response to changes in demand for applications using the Horizontal Pod Autoscaler (HPA).
- Cluster autoscaler – As opposed to scaling the number of running pods in a cluster, the cluster autoscaler is used to change the number of nodes in a cluster. This helps manage the costs of running Kubernetes clusters across cloud and edge infrastructure.
- Vertical pod autoscaling – the Vertical Pod Autoscaler (VPA) works by increasing or decreasing the CPU and memory resource requests of pod containers. The goal is to match cluster resource allotment to actual usage.
Worth noting for those running centralized workloads on single clusters: a multi-cluster approach might become a requirement for scaling if a company’s application threatens to hit the ceiling for Kubernetes nodes per cluster, currently limited to 5,000.
Cost
Another advantage to a distributed multi-cluster strategy is fine-grained control of costly compute resources. As mentioned above, this can be time-dependent, where global resources are spun down after hours. It can be provider-dependent, where workloads can take advantage of lower cost resources in other regions. Or it can be performance-dependent, whereby services that aren’t particularly sensitive to factors like performance or latency can take advantage of less performant, and less costly, compute resources.
Isolation
A multi-cluster deployment physically and conceptually isolates workloads from each other, blocking communication and sharing of resources. There are several reasons this is desirable. First, it improves security, mitigating risk by limiting the ability of a security issue with one cluster to impact others. It can also have implications for compliance and data privacy (more on that below). It further ensures that the compute resources you intend for a specific cluster are, in fact, available to that cluster, and not consumed by a noisy neighbor.
But by far the most common rationale behind workload isolation is the desire to separate development, staging/testing and production environments. By separating clusters, any change to one cluster affects only that particular cluster. This improves issue identification and resolution, supports testing and debugging, and promotes experimentation and optimization. In short, you can ensure a change is working as expected on an isolated cluster before rolling it into production.
As noted, this isolation is an inherent benefit of multi-cluster vs single cluster deployments, and not particularly dependent on how widely distributed those clusters are – you could have isolated stage/test/production clusters in a centralized hosting environment, for example. That said, when you distribute multiple clusters, this isolation can have important implications.
Compliance Requirements
Compliance is a critical consideration for many organizations. It can be closely related to isolation – workload isolation is required for compliance with standards such as PCI-DSS, for example – but it also has broader implications in regard to distributed or multi-region workloads.
In this instance, different countries and regions have unique rules and regulations governing data handling, and a distributed multi-cluster topology facilitates a region-by-region approach to compliance. A notable example is the European Union’s General Data Protection Regulation (GDPR), which governs data protection and privacy for any user that resides in the European Economic Area (EEA). Importantly, it applies to any company, regardless of location, that is processing and/or transferring the personal information of individuals residing in the EEA. For instance, GDPR may regulate how and where data is stored, something that is readily addressed through multiple clusters.
Similarly, other regulatory or governance requirements might stipulate that certain types of data or workloads must remain on-premises; a distributed multi-cluster topology allows an organization to meet this requirement while simultaneously deploying clusters elsewhere to address other business needs (to the edge for lower latency, for example).
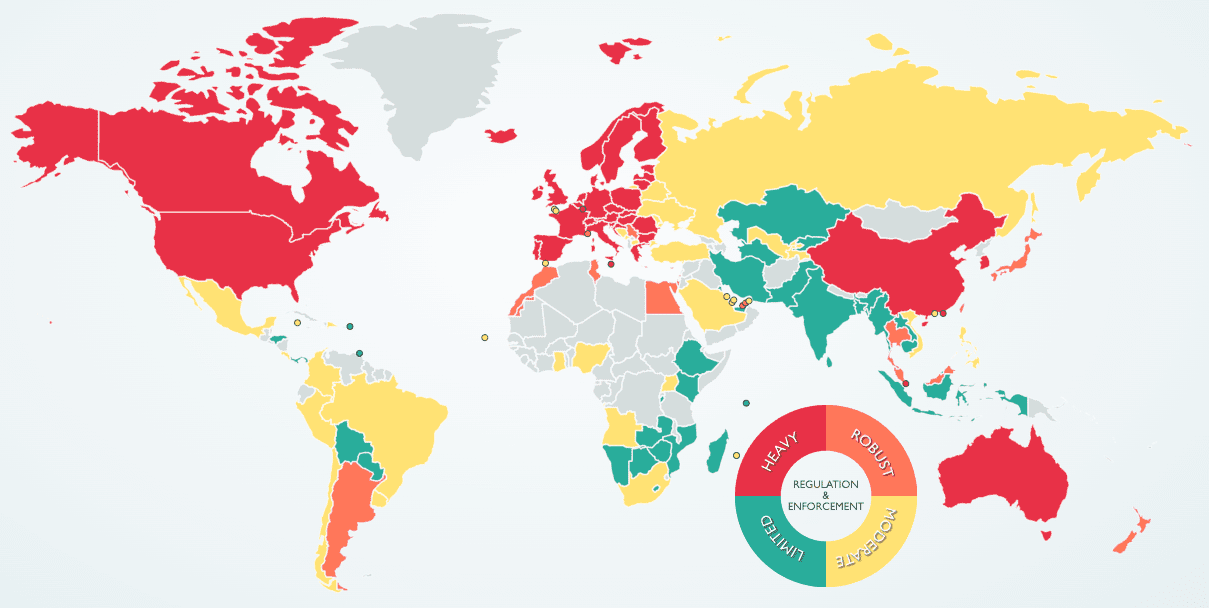
Image source: DLA Piper Data Protection Laws of the World interactive tool
Application Architecture Approaches
When it comes to selecting an application architecture for your distributed multi-cluster deployment, you have two basic choices: a replicated architecture or service-based (sometimes called segmented) approach. Which approach you select can have a profound implication for whether and how you can take advantage of all that a distributed multi-cluster topology has to offer.
Replicated Architecture
The simplest way to handle a distributed multi-cluster deployment is to replicate the complete application across multiple different Kubernetes clusters. Each cluster is an exact copy – a replica – of the others, and can be physically proximate or distant from each other, as required. Load balancers allocate traffic between the clusters, typically based on origination.
 Image source: Implementing replication using a multi-cluster Kubernetes architecture (Bob Reselman, CC BY-SA 4.0)
Image source: Implementing replication using a multi-cluster Kubernetes architecture (Bob Reselman, CC BY-SA 4.0)
Assuming clusters are reasonably distributed, a replicated architecture delivers most, but not all, of the potential advantages described above. What organizations lose, because all clusters are identical, is the ability to fine-tune around performance, cost, regulatory requirements, etc.
Service-based Architecture
In a service-based application architecture, an application gets segmented into its constituent components (each a Kubernetes service) which are then assigned to specific clusters based on operational requirements. Services interact with each other across clusters, and the communication layer must be designed to appropriately route user and application traffic. If this sounds familiar, it’s because it mirrors the loose coupling typically seen with a micro-service oriented architecture.
 Image source: A multi-cluster segmentation architecture (Bob Reselman, CC BY-SA 4.0)
Image source: A multi-cluster segmentation architecture (Bob Reselman, CC BY-SA 4.0)
A service-based architecture has distinct advantages and disadvantages over a replicated architecture. Its advantages are primarily improved isolation and granular control of data, workloads and compute resources, which in turn facilitate performance tuning/optimization, compliance, testing/production, troubleshooting, security, etc. It’s simply more versatile and flexible.
The downside of this approach is added complexity in design and management. But these issues can be mitigated with the right partner.
Distributed Multi-Cluster Edge Deployment
Ultimately, there are substantial benefits to be had in moving to a multi-cluster Kubernetes topology, and these advantages come together in the form of distributed edge computing. Nothing else delivers the same level of availability, resilience, reduced latency, geographic flexibility, improved isolation, elimination of lock-in, etc.
Organizations looking to take full advantage of edge computing while avoiding the complexity that can be inherent in deploying and operating a service-based architecture or distributed network often need to partner with a provider that understands and can mitigate these challenges. For many, the CloudFlow Edge as a Service (EaaS) solution from Webscale is the fastest and simplest path forward.
Webscale CloudFlow’s EaaS accelerates deployment of your application to the edge through a service-based architecture, allows you to use familiar tooling and methodologies, and provides centralized visibility and simplified management. You gain immediate access to our global network of providers, the sophisticated Webscale CloudFlow control plane, and our patent-pending Adaptive Edge Engine, which intelligently and continuously tunes and configures your edge delivery network to ensure optimal workload placement and efficiency.
Steadily increasing demands on application workloads are driving many organizations to modernize application delivery by embracing multi-cluster Kubernetes deployments across distributed edge cloud topologies. Companies that want to take advantage of the inherent cost, performance and availability benefits without needing to master distributed systems management should look to Webscale’s CloudFlow EaaS as the solution.
![]() A scalable, and secure solution for deploying and managing containerized applications on public, private or multi-cloud infrastructure.
A scalable, and secure solution for deploying and managing containerized applications on public, private or multi-cloud infrastructure.
Designed as a PaaS (Platform-as-a-Service) to run high-performing applications at the lowest cost by proactively monitoring compute resource utilization and automatically rightsizing infrastructure.
Purpose built to enable businesses to optimize cloud-agnostic application delivery in dense containerized environments.
Webscale CloudFlow combines three core patented technologies: Kubernetes Edge Interface (KEI) for simplified container management, Adaptive Edge Engine (AEE) for AI-enabled workload placement, and an available Composable Edge Cloud (CEC) for scalable compute capacity across the cloud vendors of your choice.