




One of the central observations we made in our recent blog post about Edge Computing Challenges for Developers was the need for familiar tooling, noting that if developers are forced to adopt entirely different tools and processes for distributed edge deployment, it creates a significant barrier. Efficient edge deployment requires that the overall process – including tooling – is the same as, or similar to, cloud or centralized on-premises deployments.
The exponential growth in Kubernetes adoption means it’s arguable that Kubernetes skills are the most in-demand skill set for IT professionals today. However, soaring adoption of Kubernetes has also led to the emergence of more and more fully-managed Kubernetes solutions from hyperscalers, edge computing platforms, and managed service providers. The maturation of these managed solutions has abstracted much of the low-level operations work, such that the skills required to effectively run Kubernetes clusters in a sense equate to expertise with specific tooling such as Helm, Prometheus Operators, CI/CD tools, etc.
In fact, as Kubernetes adoption continues to grow, Kubernetes-native tooling is becoming a fundamental requirement for application developers. Kubernetes native technologies generally work with Kubernetes’ CLI, that can be installed on the cluster with the popular Kubernetes package manager, Helm, and can be seamlessly integrated with Kubernetes features such as RBAC, Service accounts, Audit logs, etc.
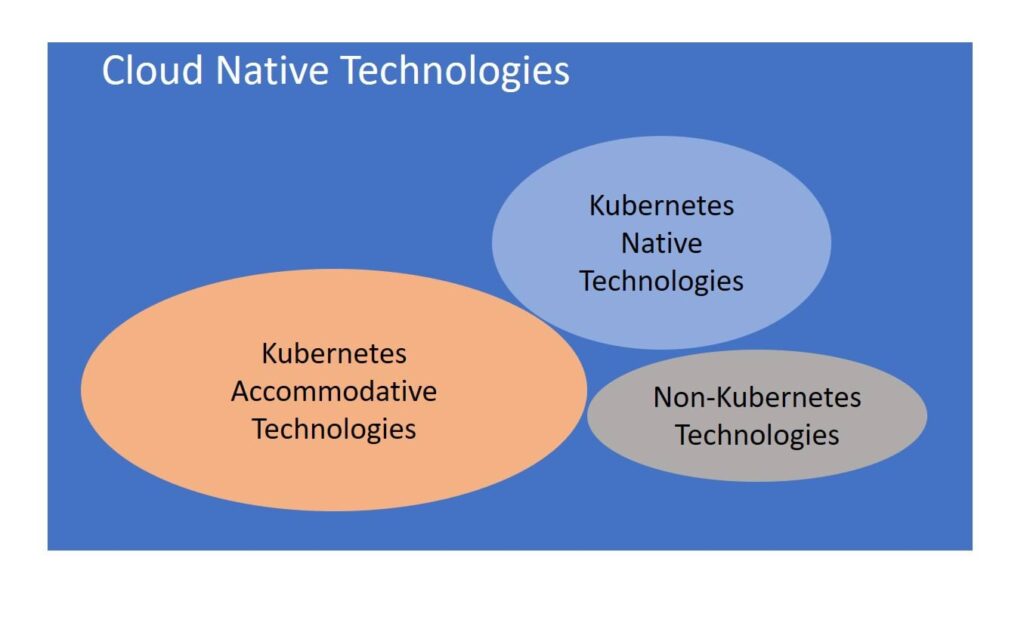
In that sense, while a solid understanding of Kubernetes is still very important, a focus on containerization itself (i.e., the Dev side of DevOps) and the tooling necessary to achieve this is perhaps the more critical skillset. Being able to build and integrate microservices into DevOps life cycles, and incorporate critical functionality like automatic feature rollouts with zero downtime and container health checks, is a skill that has significant versatility across organizations who are using Kubernetes in production today.
Another one of our recent posts touches on the challenge that the use of this familiar tooling, like CI/CD solutions (e.g., Jenkins, CircleCI), API-backed CLIs (e.g., kubectl), package managers (e.g., Helm, Kustomize), etc., poses when it comes to the edge. Simply put, what’s achievable with a single cloud instance becomes significantly more complex at the edge, where you can be running hundreds of clusters, with different microservices being served from different edge locations at different times. How do you decide on which edge endpoints your code should be running? How do you manage across heterogeneous provider networks?
Helm Chart Enablement
Let’s take the example of Helm Charts, which are an excellent tool for automating Kubernetes deployments. Yet even if you’re using Helm, the level of complexity quickly escalates when deploying applications across multiple clusters, regions, providers and environments.
At Webscale, our overriding goal is to eliminate edge complexity. We believe all you should have to do for edge deployment is simply hand over your application manifest, make some strategic settings choices, and then leave it to Webscale CloudFlow to run your applications performantly, reliably, securely, and efficiently.
CloudFlow’s new Kubernetes Edge Interface (KEI) ingests your existing Helm Charts and intelligently distributes and scales your containerized applications across a Composable Edge Cloud (CEC), providing:
- Multi-cluster support across a flexible Composable Edge Cloud (CEC)
- Intelligent workload placement and traffic routing
- Kubernetes-native tooling
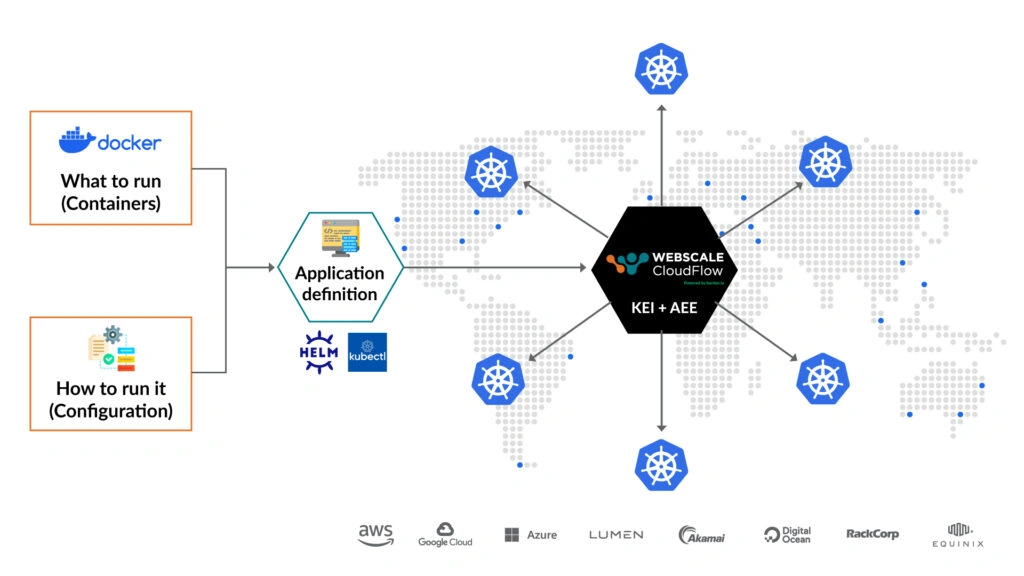
Ultimately, familiar workflows help you move faster – especially when they integrate with your current processes. To learn more about our out-of-the-box Helm Chart support, and see just how easily it allows you to configure and manage your edge deployments with Kubernetes-native tooling, request a demo.







