




Capacity planning is a challenge that every engineering team faces when it comes to ensuring the right resources are in place to handle expected (and unexpected) traffic demands. When demand for your application or website is increasing and you need to expand its accessibility, storage power, and availability levels, is it better to scale horizontally or vertically?
That decision depends on a number of factors. Is request volume steadily growing and/or is the current growth experiencing spikes that lead to service degradation. These types of considerations, coupled with an application’s unique make-up, need to be evaluated when determining the optimal scaling approach.
What is scalability?
The scalability of an application can be measured by the number of requests it can effectively support simultaneously. The point at which an application can no longer handle additional requests effectively is the limit of its scalability. This limit is reached when a critical hardware resource runs out, requiring different or more machines. Scaling these resources can include any combination of adjustments to CPU and physical memory (different or more machines), hard disk (bigger hard drives, less “live” data, solid state drives), and/or the network bandwidth (multiple network interface controllers, bigger NICs, fiber, etc.).
Scaling horizontally and scaling vertically are similar in that they both involve adding computing resources to your infrastructure. There are distinct differences between the two in terms of implementation and performance.
What’s the main difference?
Horizontal scaling means scaling by adding more machines to your pool of resources (also described as “scaling out”), whereas vertical scaling refers to scaling by adding more power (e.g. CPU, RAM) to an existing machine (also described as “scaling up”).
One of the fundamental differences between the two is that horizontal scaling requires breaking a sequential piece of logic into smaller pieces so that they can be executed in parallel across multiple machines. In many respects, vertical scaling is easier because the logic really doesn’t need to change. Rather, you’re just running the same code on higher-spec machines. However, there are many other factors to consider when determining the appropriate approach.
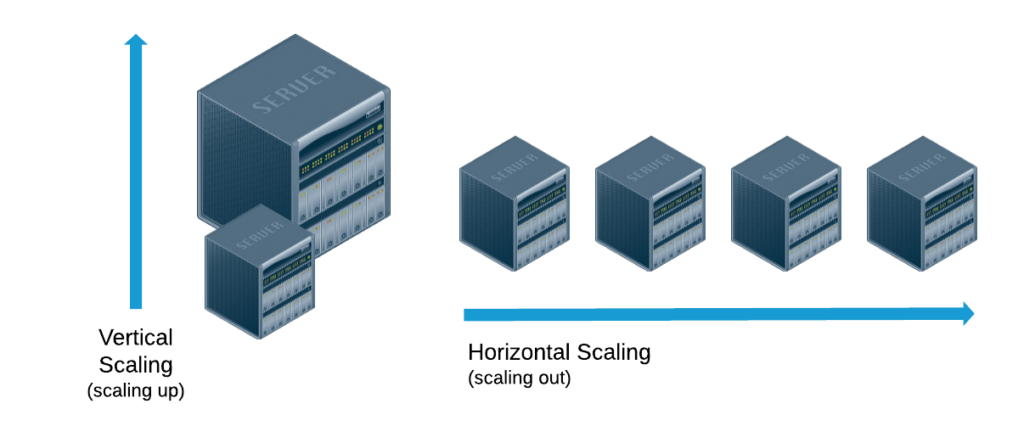
| Horizontal Scaling (scaling out) |
Vertical Scaling (scaling up) |
|
|---|---|---|
| Databases | In a database world, horizontal scaling is usually based on the partitioning of data (each node only contains part of the data). | In vertical scaling, the data lives on a single node and scaling is done through multi-core, e.g. spreading the load between the CPU and RAM resources of the machine. |
| Downtime | In theory, adding more machines to the existing pool means you are not limited to the capacity of a single unit, making it possible to scale with less downtime. | Vertical scaling is limited to the capacity of one machine, scaling beyond that capacity can involve downtime and has an upper hard limit, i.e. the scale of the hardware on which you are currently running. |
| Concurrency | Also described as distributed programming, as it involves distributing jobs across machines over the network. Several patterns associated with this model: Master/Worker*, Tuple Spaces, Blackboard, MapReduce. | Actor model: concurrent programming on multi-core machines is often performed via multi-threading and in-process message passing. |
| Message passing | In distributed computing, the lack of a shared address space makes data sharing more complex. It also makes the process of sharing, passing or updating data more costly since you have to pass copies of the data. | In a multi-threaded scenario, you can assume the existence of a shared address space, so data sharing and message passing can be done by passing a reference. |
| Examples | Cassandra, MongoDB, Google Cloud Spanner | MySQL, Amazon RDS |
*See the ongoing discussion around the need to change the Master/Slave terminology, leading to its removal in 2018 from the Python Programming Language.
The decision to scale out or scale up
In choosing between the two, there are various factors to consider. These include:
- Performance – Scaling out allows you to combine the power of multiple machines into a single virtual machine with the combined power of all of them. This means you’re not limited to the capacity of a single unit. First, however, it’s worth working out if you have enough resources within a single machine to meet your scalability needs.
- Flexibility – If your system is solely designed for scaling up, you are effectively locked into a minimum price set by the hardware you are using. If you want the flexibility to choose the optimal configuration setup at any time to optimize cost and performance, scaling out might be a better option.
- Regularity of Upgrades – Again, flexibility is important here. Building an application as a single large unit will make it more difficult to add or change pieces of code individually without bringing the entire system down. In order to deliver a more continuous upgrade process, it’s easier to decouple your application and horizontally scale.
- Redundancy – Horizontal scaling offers built-in redundancy in comparison to having only one system in vertical scaling, and thus a single point of failure.
- Geographical Distribution – When you need to spread out an application across geographical regions or data centers in order to reduce geo-latency, comply with regulatory requirements, or handle disaster recovery scenarios, you don’t have the option of putting your application in a single box. You have to distribute it.
- Cost – As more large multi-core machines enter the market at significantly lower price points, consider if there are instances in which your application (or portions of your application) can be usefully packaged in a single box and will meet your performance and scalability goals. This might lead to reduced costs.
In conclusion: a seamless transition between the two models?
It doesn’t always make sense to choose between horizontal and vertical scaling. Moving between the two models is often a better choice. For instance, in storage, we often want to switch between a single local disk to a distributed storage system.
Building flexibility into the system, where some layers of the application run on vertically scaled machines and other layers on horizontally scaled infrastructure remains a matter of designing for parallelization. To achieve this, (i) design it from the outset as a decoupled set of services, making the code easier to move, meaning you can add more resources when needed without breaking the ties between your code sets; (ii) partition your application and data model so the parallel units don’t share anything.
It’s likely that the industry will increasingly migrate towards a horizontally distributed approach to scaling architecture. This trend is driven by the demand for more reliability through a redundancy strategy, and the requirement for improved utilization through resource sharing as a result of migration to cloud/SaaS environments. However, combining this with a vertical scaling approach can allow us to benefit from both paradigms.







